Recently in his blog post "Microservices. The good, the bad and the ugly", Sander Hoogendoorn warned us about the versioning hell of microservices. He wrote:
“Another that worries me is versioning. If it is already hard enough to version a few collaborating applications, what about a hundred applications and components each relying on a bunch of other ones for delivering the required services? Of course, your services are all independent, as the microservices paradigm promises. But it’s only together that your services become the system. How do you avoid to turn your pretty microservices architecture into versioning hell – which seems a direct descendant of DLL hell?”
I wrote almost the same in an internal discussion late last year in my team. In my internal memo “Transient States Testing Challenge”, I warned that this problem is emerging as a component gets split into a few smaller pieces (aka. microservices), the testing cost may increase substantially and we must understand and prepare for it. Here is the full text of the memo (with sensitive details removed):
Before
When it was just a one piece, say it’s a service X, there would be no transient state. During the upgrade, we will put the new binaries of X to a dormant secondary. Only when the secondary is fully upgraded, we will promote it to primary (by switching DNS, like the VIP Swap Deployment on Azure) and the demote the original primary to secondary. That promote/demote is considered instant and atomic:

Looking inside the box, X consists of five pieces: say A, B, C, D and E. When each of the five teams is developing their own v2, they only need to make sure their v2 code can work with the v2 code of others. For example, team A only needs to test that A2 works with B2, C2 and D2, which is the final state {A2, B2, C2, D2}.

Team A doesn’t need to do integration test of A2 with B1, C1 and D1, because that combination would never happen.
After
As we are splitting X into smaller pieces, each smaller piece will be independently deployable. The starting state and final state remain unchanged but because there is no way to strictly fully synchronizing their upgrades, the whole service will go through various transient states on the path from the starting state to the final state:

In an overly simplified way (for the convenience of discussing the problem), there are two choices in front of us:
Choice #1: Only deploy the four of them in a fixed order, and only one at a time. For example, A->C->D->B and the transition path will be:

Therefore, in testing, not only we need to make sure {A2, B2, C2, D2} can work together, we will also need to test three additional states:
- {A2, B1, C1, D1}
- {A2, B1, C2, D1}
- {A2, B1, C2, D2}
The amount of additional states to test equals N-1 (where N is the number of the pieces). The caveat of this approach is that we are losing the flexibility regarding the order of deployments. If C2 deployment is blocked, D2 and B2 are blocked, too. That’s against agility.
Choice #2: Not to put any restriction on the order. Any piece can go at any time. That gives us the flexibility and helps agility, at the cost of having to do a lot more integration testing to cover more transient states:
- {A2, B1, C1, D1}
- {A1, B2, C1, D1}
- {A1, B1, C2, D1}
- {A1, B1, C1, D2}
- {A2, B2, C1, D1}
- {A2, B1, C2, D1}
- {A2, B1, C1, D2}
- {A1, B2, C2, D1}
- {A1, B2, C1, D2}
- {A1, B1, C2, D2}
- {A1, B2, C2, D2}
- {A2, B1, C2, D2}
- {A2, B2, C1, D2}
- {A2, B2, C2, D1}
The amount of additional states to test equals 2^N-2 (where N is the number of the pieces): N=3 -> 6; N=4 -> 14; N=5 -> 30; .... That’s getting very costly.
Possible Optimizations?
We could have some optimizations. For examples:
- Among the four pieces (A, B, C and D), make some of them orthogonal, to eliminate the need of testing of some transient states.
- Find a middle ground between following a fixed order vs. allowing any kind of order. For example, we can say A and B can go in any order between them and C and D can go in any order between them, but C and D must not start the upgrade until both A and B are finished. That will reduce the number of possible transient states.
- ...
But these optimizations only make the explosion of permutations less bad. They don’t change the fundamentals of this challenge: the need of testing numerous transient states.
Backward Compatibility Testing?
Another possible way to tackle this is to say that let’s invest in the coding-against-contract and backward compatibility test of A, B, C and D so that we can fully eliminate the need of testing the transient states. That’s true, but it brings in its own costs and risks:
1. Cost
By suggesting investing in backward compatibility test to get away with the testing of numerous transient states, we are converting one costly problem to another costly problem. As a big piece splits into smaller one, the sum of the backward compatibility test cost of all the smaller pieces is going to be significantly more than the original backward compatibility test cost when we have just 1 piece.
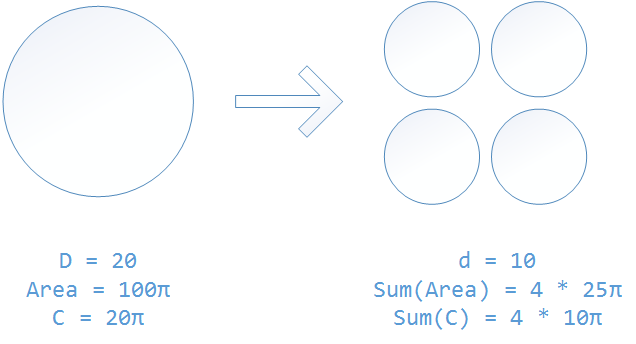
That’s just plain math. In backward compatibility test, you are trying to make sure the circle is friendly with its surrounding. When a big circle splits into multiple smaller circles while keep the total area unchanged, the sum of the circumferences of the smaller circles is going to be much bigger than the circumference of the original big circle:
2. Risk
Only validating against contract can cause missing some very bad bugs, mainly because it’s hard to use contracts to capture some small-but-critical details, especially those behavioral details.
Testing in Production?
One may suggest that we do neither: not to test all the permutations in transient states, nor do that much backward compatibility testing between microservices. Instead, why don't we ship into production frequently with controlled small exposure to customers (aka. flighting, first slice, etc.) and do the integration test there? True but still, we are converting one costly problem to another costly problem, since testing in production also requires a lot of work (in design and in testing), plus engineering culture shift.
What's my recommendation?
No doubt that we should continue to move away from the one big monolithic piece approach. However, when we make that move, we need to keep in mind the transient states testing challenge discussed above and look for a balanced approach and the sweet spot in the new paradigm.
Comments on “The Versioning Hell of Microservices”