Someone was asking on Quora about how manage the migration of data when there is a database schema change. I shared how we did in a real data migration project back in 2006/2007. It was a payment system (similar to today's stripe.com, but ours wasn't for the public) that ran on .NET XML Web Service + SQL Server. In a much simplified way for ease of writing:
- It had a
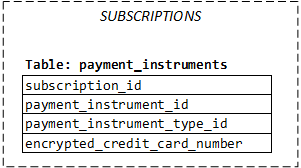
Subscriptionsdatabase, in which there is thepayment_instrumentstable, where we stored encrypted credit card numbers. - Having
subscription_idon thepayment_instrumentstable implied that we assume every payment instrument must belong to one and only one subscription.
Now we wanted to support standalone payment instruments, which doesn't belong to a subscription. So we needed to migrate the payment instrument data into a new payment_methods table in a new Payments database:
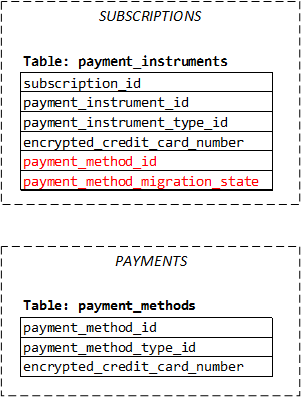
It was a very successful data migration project. It had done quite a few things right, which I will repeat in any future data migration projects:
- We kept the old
payment_instrumentstable. We added a newpayment_method_idfield to thepayment_instrumentstable, so that thepayment_instrumentstable acts as a proxy. The benefit is: we can keep most of the legacy code untouched, which can continue consume thepayment_instrumentstable. We just need to change the data access layer a bit, to back fill the encrypted credit card number from the newpayment_methodstable, when all other legacy code is querying thepayment_instrumentstable. - We added a
payment_method_migration_statefield to the oldpayment_instrumentstable. This field is to indicate whether the old or the new table is the source of truth. We used an explicit field to be the indicator, rather than use an inferred value (for example, by looking at whether theencrypted_credit_card_numberfield is null in the oldpayment_instrumentstable), because an explicit and dedicated indicator of migration status is much less confusing than inferred status, which is usually more error prone because it gives something already in use a new meaning (on top of the original meaning). Also, the explicit indicator serves as a lock a little bit: when a migration is in progress, some update operation should be blocked. - We use both online and offline migration. Online migration: any time a mutation API is called on a payment instrument, such as
UpdatePaymentInstrumentorPurchaseOffering(with a certain payment instrument), the migration code is triggered and runs in the Web frontend, which insert row topayment_methodstable, copy over theencrypted_credit_card_numbervalue, back fill thepayment_method_idin the old table and set thepayment_method_migration_state. Offline migration: we have a standalone tool running in our datacenter, which go through the existing payment instruments and migration them one by one. The reason we had offline migration on top of online migration was because some customers only used our system very infrequently, such as once every three months. We don't want to wait for three months to migration their data. - Controlled migration at per-customer level. We designed it in a way that we can select a batch of customers to be eligible to do the migration (in both online and offline). In that way, we can start with a very small number (say 100 customers), and expand to 1000, 10000, 10% of the system, then all. We did find some critical bug during the first several small batches.
- Due to compliance requirement, we must not keep the
encrypted_credit_card_numberdata on the old table. But we didn't do the deletion until the entire migration is done done. That's because if anything seriously goes wrong, we still have chance (even just in theory) to go back to the old data schema. Actually, we did have some bug which messed up data (puttingencrypted_credit_card_numberon the wrongpayment_method_id) and having kept the old data allowed us to redo the migration correctly. It saved the day. - We made the two new fields on the old
payment_instrumentstableNullable, rather than a default value, to prevent the data page from rearranging for the existing rows (nearly hundreds of millions of them). For the same reason, when we removed theencrypted_credit_card_numberdata on the old table, we didn't delete it but set it to an all-spaces string which has the equal width as the original encrypted blob. - During testing, we modified the deployment script to be able to deploy both old and new version of the frontend side by side. Because the
AddPaymentInstrumentAPI in the new version will always put data in the new schema. We needed the ability in our test automation to create data in the old schema, in order to test the migration code. This ability is actually not only useful in data migration project, it's generally useful in online services: it's always good to know whether the data created by older version(s) can be correctly handled by the new version.
The above 7 things that we have done right will be applicable to future data migration projects that I will do. #6 (preventing data page from rearranging) may be specific to SQL Server, but its spirit is widely applicable: better understand the underlying implementation of the database system, to minimize the performance hit when migrating non-trivial amount of data or touching a lot of rows.
Besides, two more takeaways of mine are:
- Have the right expectation. Data migration will be hard. After spending all the time in design, implementation and testing, the actual migration will also take a lot of time. In our project, we ran into weird data patterns in production that we never thought it would be possible. It turned out to be the result of some old code which is now gone (either retired, or fixed as a bug). In production, we also discovered quite some bugs in our migration code that were hard to discover in test environment. It takes many iterations to discover them, fix, test the fix, roll-out the new bits, resume the migration and discover a new issue. It would be helpful if you could get a snapshot of full production data to test your migration code offline. But in some cases, due to security/privacy/compliance, the data to be migrated must not leave the production data center and sanitizing it will defeat the purpose.
- Do not do migration of frontend and database at the same time. If you must abandon both the old frontend (e.g. REST API, Web UI, etc.) and old database, do it in two steps: First, do the data migration. Keep the frontend unchanged to customers, and only change the frontend code under the hood to work with the new database. Second, build a new frontend on top of the new database. For sure the two-steps way sound more costly. But in my experience (I have done both ways in different projects), the two-steps way counter-intuitively will end up more cost efficient, less risky, more predictable and more under control.
