题图:思南路别墅
绘于:2020年4月17日
学习笔记之一:我们是怎么认识 0 的
学习笔记之二:细节消失,抽象生成
学习笔记之三:卷积像卷地毯
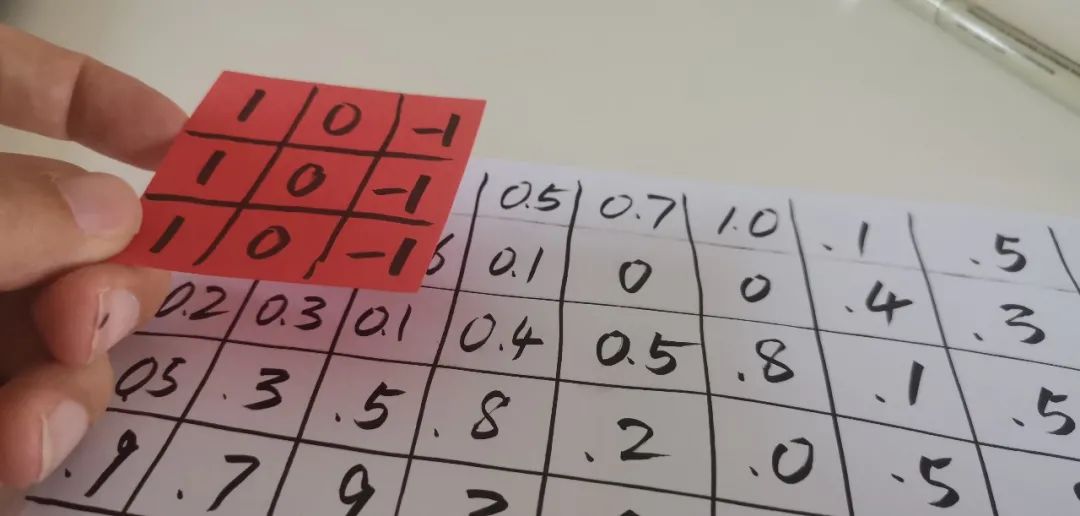
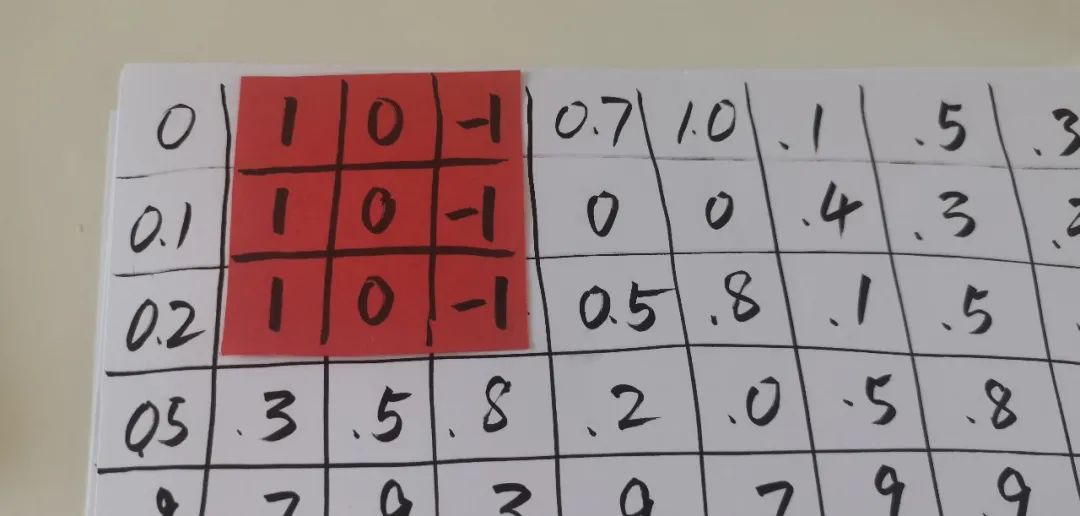
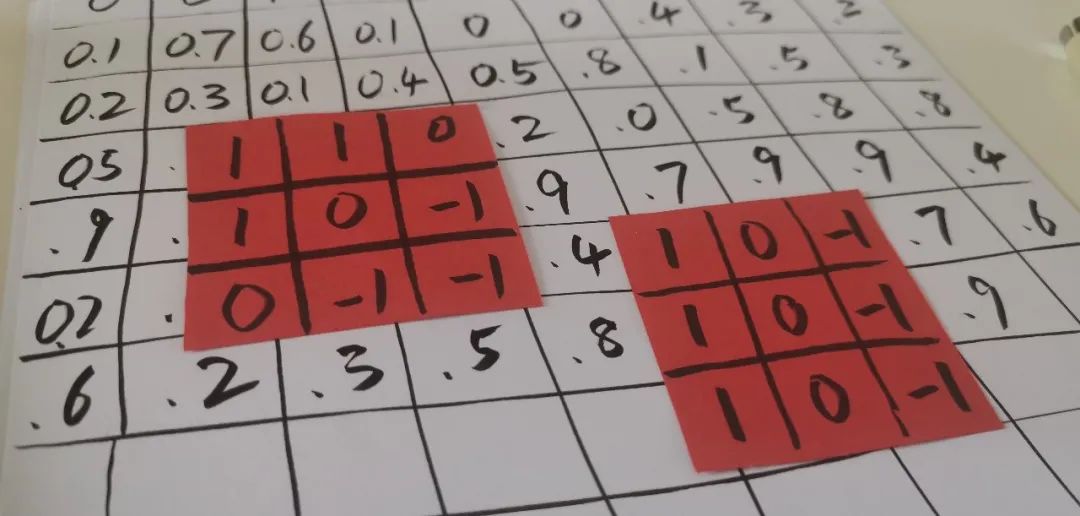
上一次走到了卷积网络的第一步,就是用一个 3×3 的小矩阵就像探照灯一样,把图像扫一遍,就得到了第二层的网络。
第一层对于黑白的图像只有一个深度(depth),就是灰度值,对于第二层网络已经增加到了 32 层深,分别对应于在 32 个不同的 filter 上的匹配程度。我们这次接着深入。
ReLU (灯泡亮了!)
不知道是谁用灯泡💡来表示脑子里面的一个新主意,真是一个非常好的比喻,就是当一个想法诞生的时候,就觉得是脑子里面什么地方的一个小灯泡忽然亮起来了。
前面的卷积,生成的结果就算再复杂,也是按照线性函数来推倒的,就是 y = a * x + b ,再怎么变化多端,都还是一个线性函数。有人就提出来了,大脑的神经网络应该不是这么工作的。应该引入一些非线性的东西。这就是 ReLu 激活。(ReLU = Rectified Linear Unit)
这个函数简单得很,就是:当输入小于 0 的时候,输出为零。但输入大于 0 的时候,输出是这个数。用代码表示就是:
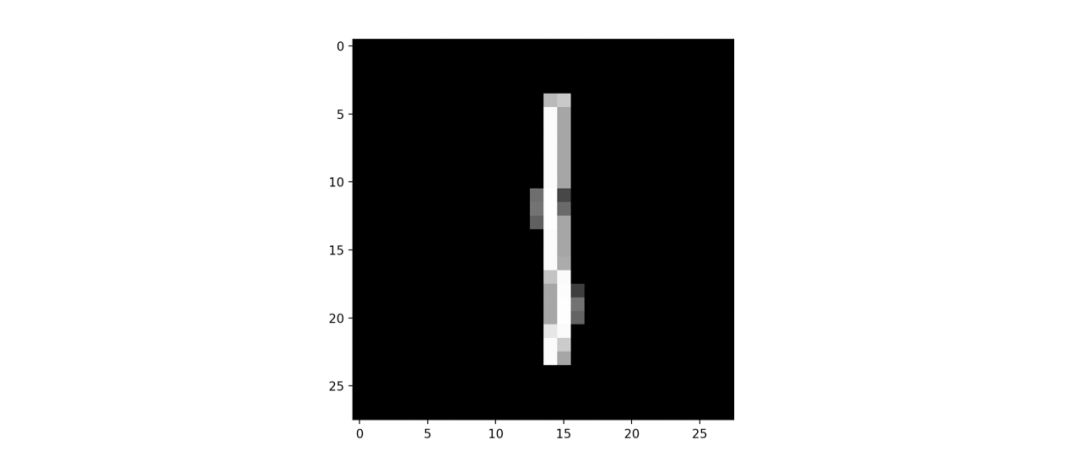
这个就有效的把无关的信息给简化和屏蔽了。对于竖线的检测函数,如果我没有检测到竖线,我就输出为 0 , 而不再输出负向的信息了。也就是说,如果我看到了有人做好事,我就叫出来;如果有人做坏事,我就当没看见,也不会去举报你。
这就很像脑子里面的那个灯泡 💡,当几个输入的结果合并起来使得输出高过一个阈值的时候,下一层相应的神经元就被点亮(激活),如果没有超过的话,就继续暗淡下去。这个很简单的函数给整个系统带来了难得的非线性,就可以有一些逻辑运算的感觉在里面了。
我们构建的四层神经网络
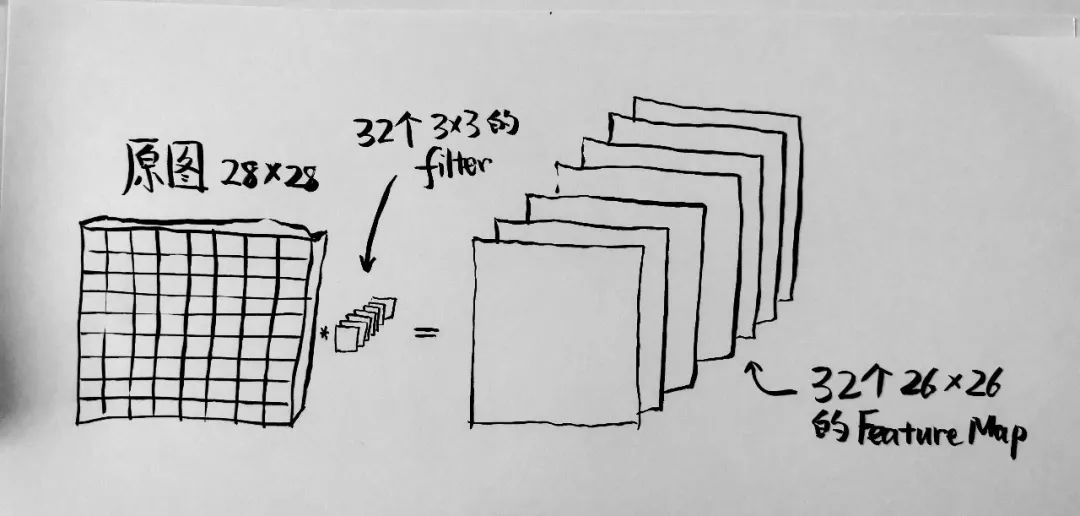
model = Sequential()model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
上面的代码,就是建设了一个 Conv2D 的模型,这个模型的 filter 数量是 32, kernel_size,就是这个 filter 的大小,是 3 x 3 , 激活函数使用了 relu ,并且接受一个输入为 28 x 28 x 1 的矩阵(就是那个图像),输出一个 26 x 26 x 32 的矩阵。宽和高从 28×28 变成了 26×26 是因为用一个 3×3 的矩阵向右挪的时候自然会失去最左和最右的两列,就像一个 4×4 的矩阵用一个 3×3 的矩阵去滑动的话只能滑动一格,结果变成 2×2 的矩阵一样。
model.add(MaxPooling2D(pool_size=(2, 2)))
我们继续解释代码。下一个就是 MaxPooling2D 的功能。这个更简单的了。就是拿一个(2,2)的区域,找到其中最大的那个数,输出出来,把原来四个像素的位置合并成一个像素,并且把这个数字填进去。这个就是简单粗暴的把一个 26×26 的矩阵缩成了一个 13×13 的矩阵。
从逻辑上讲,这就是忽略细节的过程。我们看一个数字的时候,隐隐约约的觉得左上角有辆车,至于它精确的在什么位置,长什么样子,不重要,重要的是, 左上角有一辆车。他就是把得出的 32 个图像的大小都缩小一半,但是信息都保留(就是最大的,已经找到的那个模式)。
Flattern
这个一个比一个简单,就是把所有的数字从矩阵排成一个一维数组。前面的输出是一个 13 x 13 x 32 的一个矩阵,通过这一层,变成了一个 5408 个数字数组。就像把麻将桌中间的一堆麻将在自己面前一字排开那样。
全联接层
model.add(Dense(10, activation='softmax'))
最后的这一个层叫做全联接层,就是把前面的5408个数字和最终结果的10个数字做一个每一个节点和另外一层的每一个都连接起来,找到一个系数,找到 y = a * x + b 这样的关系。
就是说,对于结果的第一个数字,是前面5408个数字和5408个系数(a1, a2, a3, …, a5048) 相乘并且把结果相加,再加上一个数字(b)得来。这一层的参数最多,需要(5408 + 1)* 10 = 54090 个参数才可以完成。相比之下,前面的 (3 x 3 + 1)x 32 = 320个参数算是精简得不得了。
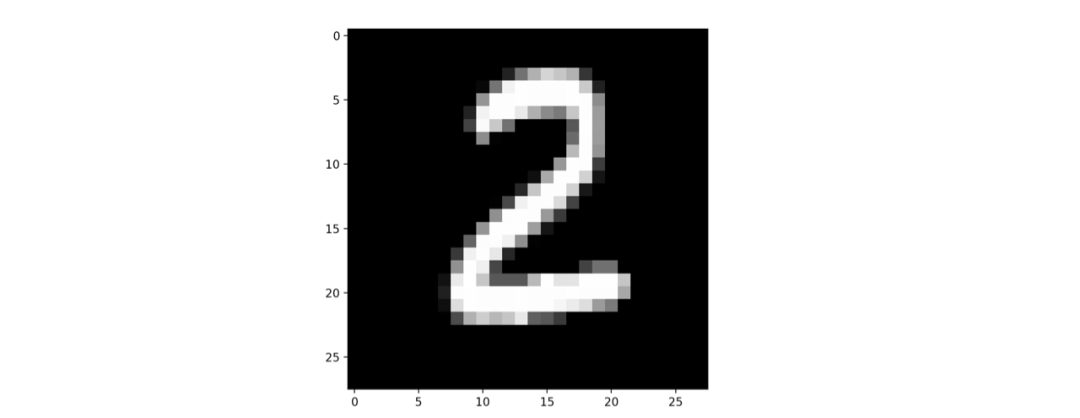
这一层最终是10个数字,对应着答案的十个数字,作为这个模型的第四层,也是最后一层,经过一个叫做 softmax 的激活函数,它的输出是一个十个数的数组,这十个数字分别都是0-1之间的一个数字,他们的加和等于 1 , 每个数字都对应相应位置的可能性。比如上一篇的结果,就会是 2 对应的数字非常高(就是电脑认为很有可能是 2 ),而其他的都很小。
训练函数
model.compile(optimizer='adam', metrics=['accuracy'], loss='sparse_categorical_crossentropy')
现在我们就到了核心的7行代码的最后三行了。前四行分别构建了四层网络,最后就开始训练这个网络了。
compile 那一行给出了优化器,loss函数还有如何衡量好坏的函数。这些对于初学者可以暂时不考虑,就先照猫画虎就好了。
接下来,我们把现在构建的这个网络的摘要打印出来
Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0 _________________________________________________________________flatten (Flatten) (None, 5408) 0 _________________________________________________________________dense (Dense) (None, 10) 54090 =================================================================Total params: 54,410Trainable params: 54,410Non-trainable params:
从这里我们可以清晰的看到,第一层,输入一个 28x28x1 的图像,输出一个26x26x32 的图像。而深度从1变到32就是从灰度这一个维度变成了32不同的问题的答案(比如有没有竖线这样的问题)。
接下来的 MaxPooling 层,如我们刚才所说,在深度 32 不变的情况下把每一层都从 26×26 简化成了 13×13 。
在下面的 Flattern 层,把13x13x32压扁成一个长度为 5408 的数组。
最后一层再把这个数组变成长度为 10 的数组,分别对应于结果的 0 – 9 。
开始训练
到了现在,网络已经搭好了,但唯一的问题是,里面所有的参数都是 0 – 1 之间的随机数,用一个随机数构成的网络肯定准确率差得一塌糊涂了。用一个随机数作为参数的网络,当你输入一个图像,它一定也可以输出一个数字,但这个数字 10 次有 9 次是错的,对的一次也是瞎猫碰到死耗子。
为了避免随机数,接下来这一句话,才是最重要的一句话,就是开始“训练”了。
model.fit(x_train, y_train, epochs=20)
这个函数把60000个 x_train 包含的图像,还有 60000 个 y_train 代表的正确答案交给网络。刚开始的时候,答案肯定是错的。但是神经网络通过错的方向(结果太大了还是太小了)去反过去调整上一层网络的参数,然后再进一步调整再上一层的参数,直到用6000组数据把这 54,410 个参数调整到精确度最高的程度。到了训练的末期,基本上上一次训练的这些参数已经可以让下一次输入的参数以极大的可能性(99%以上)和正确答案相同了,这个训练就完成了。
下一次,我们会再把上面说的这个过程用图像可视化出来,然后再继续用比喻的方法来宏观的理解,计算机到底是怎么认识数字的。
后台回复 AI 可以获得没有发表的AI相关的文章和代码。