上一次(就像医生看化验单)我们问了一个问题但是没有回答,那就是:人工智能到底是怎么学习的?
在前面的这一系列的文章里面,我们都假设了,所有的参数都是已经学好的,就好像上帝创造了人一样,被人类创造了出来。有了第一层这几百个数字,后面几层的几万个数字,机器就如同有了灵魂一样,能够先识别边缘,再从边缘学习线,从线学习圆圈,从圆圈学习数字0,或者继续学习圆圈的组合,从而认识猫,认识人脸。
但最重要的问题还是没有回答,这些数字是怎么确定的呢?作为这个系列的最后一篇文章,希望把这个最重要的问题来回答。
淋浴调节水温的例子
举一个例子:
假设你去洗淋浴。有一个水龙头,还有一个花洒。你想洗一个温度适中的热水澡。但你也不知道这个龙头的物理结构,甚至不知道哪边是冷哪边是热。你唯一知道的是,现在的水温你不满意,比如说太热了。好在这个系统你需要训练的参数只有一个,就是那个水龙头的位置。
你往右搬了一点点,感觉一下水龙头和自己希望的水温是更近了还是更远了。比如,你觉得水更烫了,这不对。你就知道了,接下来应该往左一点。然后发现水温真的更低了。好兆头,说明我们现在的前进方向是往最终误差减少的方向前进着。那下一步,再小一点点,然后再感觉,直到到了一个地方,你继续往右,发现水温已经低于你的舒适温度了,往左,水温就会高于你的舒适温度, 那我们就在这个位置停下来了。
到了这个时候,你依然对于水龙头的工作原理一窍不通,对于流体力学和热力学更是一窍不通,但通过尝试,你好似已经物理博士毕业一样,可以精确的控制水温了。
对于简单的学习,机器基本上就靠一个字 “蒙”,当然更好听一点叫做 “试”。但试也是试的有章法的,就是机器每试一下,就把它影响的后面每一层的输出的变化记下来,来帮助自己决定,下一次尝试朝哪个方向前进。
人工智能领域的段子
有一个人工智能领域的段子,是一个人去面试一个人工智能工程师的职位,面试官和他的对话是这样的:
面试官:7 + 2 等于几?
工程师:3?
面试官:太小了
工程师:8?
面试官:还是小了
工程师:10?
面试官:大了
工程师:9.5?
面试官:大了
工程师:9.2?
面试官:你被录取了
现在估计你能看懂这个段子了。
复杂的系统
但如果要调整的不止一个水龙头,你面前放着5万个水龙头,这怎么搞?
这就是典型的训练神经网络,决定那几万个参数的时候面对的问题(几万个参数算啥呢,最近的GPT-3训练需要调整1750亿个参数呢)
继续类比,用炒股的例子来说明
我们继续举例子。假设你和一群人组成一个公司炒股。再假设这个股市完全靠消息,消息灵通的就就能赚钱。而且你们只做短线,买完以后当天就卖。
然后我们搭出来了一个金字塔结构。你是最终做决定的那个人,是金字塔的最高的一级。
在你前面,你安排了10个眼线。分别是老赵,老钱,老孙。。。。。他们每个人也有几十个眼线,分别是大周,大吴,大郑。。。。,他们每个人下面还分别有了大量的眼线,叫做小冯,小陈,小楚。。。。。只有小字辈的,能够接触到第一线的情报。
就跟任何组织一样,每个人都对自己手下的几个小弟有不同的信任程度。这个信任程度我们不妨叫做权重 w (这就是神经网络里面的那个参数)。每个人都把自己的所有的小弟报告的数字,乘以对他的信任程度(权重),相加以后把这个值再报给上一级。
开始训练
于是,这个组织成立的第一天,所有人各就各位,但是信任度还没有建立,所以所有的人都随机的选择到底多信任自己的小弟(有的根据好看程度,有的根据高矮胖廋,有的根据年纪),总之,这个信任度没有任何事实依据。你们约定,你们就想知道一支股票要不要买。如果一个人认为是 0,就是不要买,1 就是买,在这中间的一个数字,就是你要买的建议程度。
这天上午,第一次消息传过来了,经过了小字辈,大字辈,老字辈三层的不靠谱的随机信任度,最终你收到了一个数字,是 0.2 。低于0.5,你决定不买。
当天过去了,结果出来了,股票涨了!
说明正确答案是 1 ,就是该买。好。这个时候你会怎么做?
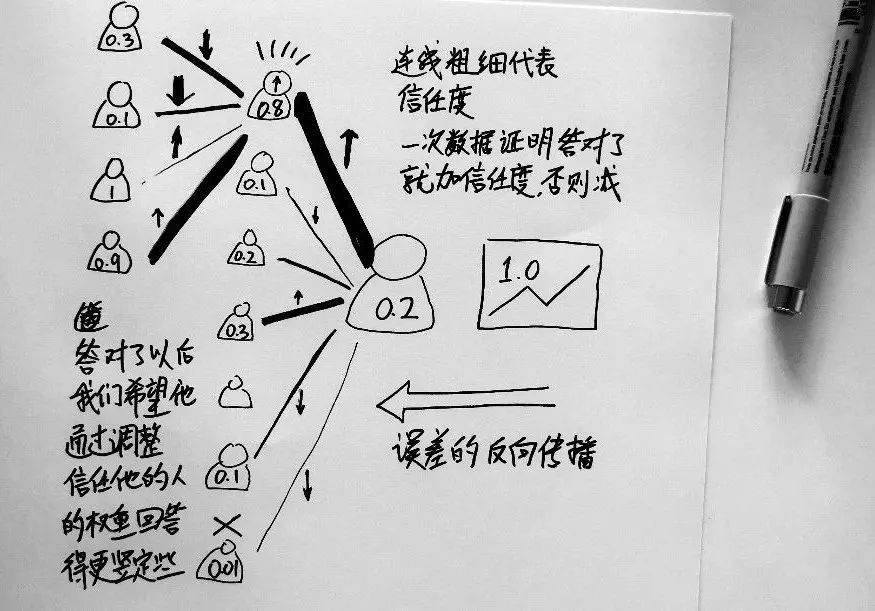
你会秋后算账。你看一下,刚才让我买的是那几个人?让我不买的又是哪几个?哦。老张当时给我的情报是 0.8,他的贡献是朝向正确的方向的。你就在心里面悄悄地把老张的信任度调高了一点点:下回还得听他的。然后看其他的老钱,老孙,给的是 0.01, 0.1,不靠谱,你把对他们的信任度稍微调低了一点点。这样,你最后一层的连接老字辈的人和你之间的参数就都发生了变动。(就像上面图上的向上和向下箭头)
人间一秒,计算机中1年。我们训练了几分钟,计算机里面已经经过了几十年。这几十年里一起炒股票,最终老张等人在你心中的可信程度已经被训练得炉火纯青了:最终你最信任老张,老张怎么说,你就乘以0.99,直接就巨大的影响你的决策。老钱差了点,但还算靠谱,乘以0.2吧。至于老孙,那是相当的不靠谱,不过你也摸到规律了,只要他让买你就卖,他让卖你就买,一直反着听,倒也效果不错,信任值稳定到了 -0.8
同样的,对于老张,因为他的权重最高,而且结果和正确结果在一个方向上,我们希望,在同样的情况下,老张应该输出的数字再大一点,因为他说话管用。但老张自己是不会输出数字的,他唯一能够调整的,是他对他的小弟们的信任程度。于是,老张干了一件和你一模一样的事情,看看他的小弟们,是谁说要买的,往上调整信任值,说错的,往下调整。这样子他下一层也会做同样操作。一直到最前面的小冯,小陈,小楚。
也是经过了几十年的训练以后,每一层的权重(就是他的上级对他的信任程度)都调得差不多了。这也就是一个训练有素的炒股团队了。每一天,无数的小弟勤勤恳恳的把自己的第一手资料传给他们的上级,而他的直接上级心里面自然有一个算盘,根据过去几十年的经验,信任一些人,不信任一些人,甚至反向信任一些人(他们说涨那是肯定会跌的),如此再往上传,一层一层传递到你这里来,你一看,你得到了0.8,赶紧买!这个准确度是多少呢?一般来说一个搭建完好的神经网络对于认数字这样的问题,做到97%以上问题不大。
总结
现在可以总结一下这个过程。
-
开始的时候所有的参数都是随机数
-
从第一次训练开始,把数据输入,然后得到一个不靠谱的输出
-
把这个输出和正确答案比一比,从最后一层开始把这个误差向前传播,微调一下信任值。
-
再进行一次训练,再调整。直到训练完成,所有参数稳定下来。
到此,这一个系列的关于人工智能的八篇文章也暂时告一段落。如下是以前的文章: