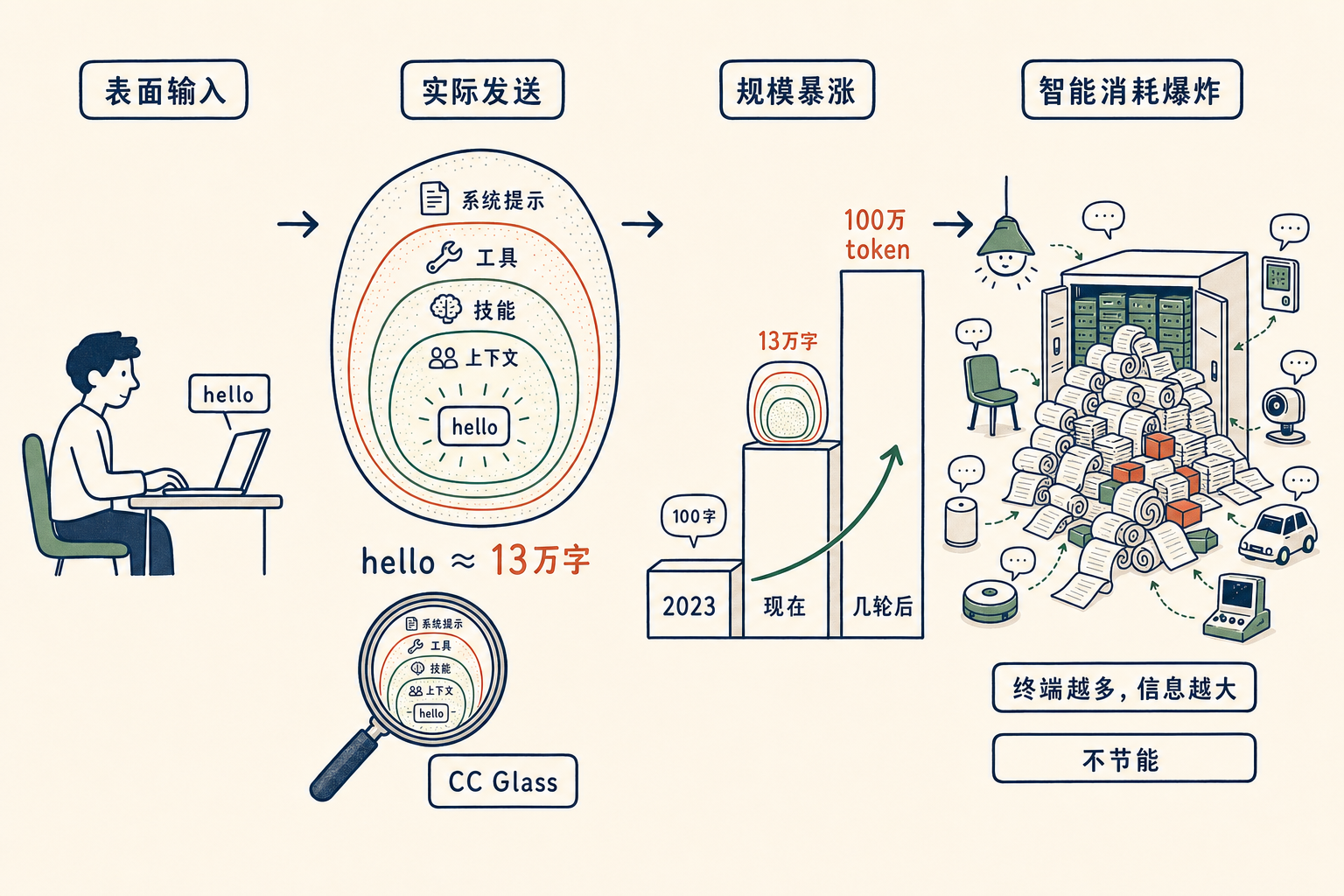
你打一个 hello,发过去 13 万字
作者:Jian Shuo Wang 发表于:2026-05-24 09:05 · 未分类
你打一个 hello,发过去 13 万字
你打开 Claude Code,或者 Codex,这些编程的工具,跟它打一个「你好」,或者「hello」,按回车。远端是一个大语言模型。
你猜,你往那边发了多少东西过去?
直觉上你会觉得,我打了一个 hello 过去,它回我一个 how are you,几十个字符的事。
我昨天用工具去看了一下。在装了一些 skill、一些工具之后,第一个 request 过去,是13 万字。
然后再往后,几轮之后,你的每一轮过去都是 100 万个 token,换算成字符就是上千万字。
一个 hello,13 万字。这中间多出来的东西,是从哪来的?
因为你打开 Claude Code,它会带上一整套东西。
有系统的 prompt,安全的、各个 section 的,反正一大坨。 有你所有的工具,它缺省就装了四十几个工具,还在不断加。 有你装的所有 skill,假设有 100 个 skill,每一个 skill 的 header 全都要编进去。 有你前面所有的上下文,所有工具处理的结果。
这些东西,裹着你那个小小的 hello,一起发了过去。
这里有个反直觉的地方。你会以为,我那些 skill 的关键词没有触发,它就不会被发过去。不是的。
所谓「触发」,本质上就是把所有的 skill 都写进去、全部扔给大语言模型。因为大语言模型对你的 skill 毫无认知,你不给它,它根本不知道这些 skill 存在。所以它必须每一次都全部带上。你装得越多,每一次 hello 拖着的尾巴就越长。
想象一下 23 年的时候,我们用 ChatGPT 是多么的纯真。每一次过去都是 100 字、100 字那么小的规模。现在你即便只打一个 hello,传过去的都是 13 万字。
如果按输入 token 数来算,从 23 年到现在,我们每一次跟大语言模型的交互,已经提升了几千倍。
而且未来你什么都不干,啪一下扔过去几百万个 token,会变成稀松平常的事。每个人都这样。
这个数量的增加,是超出人的想象的。就像 2000 年的时候,我根本无法想象现在一部剧、一帧画面的信息量——一秒钟 30 帧,其中一帧的数据量,可能就超过我当年一个月看到的所有信息的总和。
所以,所谓智能消耗的爆炸,不是一个未来的预言,它现在已经显现了。
它一点都不节能。完全不节能。
会有人去做优化,想这里怎么省一省、那里怎么压一压,这个一定会做。但大的趋势是不变的:每一次交互携带的信息量,只会越来越大。物理世界里现在还有很多东西没接进来——椅子还不会说话,灯还不会说话。等这些终端都开始交互的时候,信息量会再上一个量级。
所以最近大家都说存储的需求那么大。我们每个人拿自己这双小肉手,一天能敲出多少东西?很有限。但有了 AI 以后,一天产生的、有意义的、需要存储的东西,可能就超过人类社会以前一整年。
我最近写了个小工具,叫 CC Glass,就是用来看这件事的——把那个你以为只有 5 个字符、其实是 13 万字的 hello,照出来给自己看。
照出来之后你会发现,节能这件事,在这个方向上,可能从一开始就不在考虑范围里。