大语言模型已经是一个「自然语言对代码的编译器」
作者:Jian Shuo Wang 发表于:2026-05-18 09:10 · 未分类
大语言模型已经是一个「自然语言对代码的编译器」
大语言模型现在已经是一个精确的、自然语言对代码的编译器了。
什么叫编译器?编译器是把一种语言精确翻译成另一种语言,没有 surprise,没有歧义。你写 C,它编译出来的二进制,每次都一样。
以前我们写代码,自然语言这一层是没法做编译的。你跟工程师说「帮我改一下那个 bug」,他可能改对,也可能改歪,可能多改一些他觉得顺手的东西。这不是编译,是创作。
现在反过来。
你直接跟 Claude Code 说「帮我改这个 bug」——它干的活也是创作,没准。
但如果你先让它写一份 spec,再让它把 spec 写成 plan,再让它把 plan 拆成 task,再让一个 sub-agent 去执行——
到最后那一步,它从一份 5000 字的、被你 review 过的、精确到每个字段每个文件的 plan,变成 300 行代码的改动。这 5000 字到 300 行,不是创作,是编译。
因为 5000 字里已经写了每一行代码该做什么、不该做什么。剩下的只是「把它写出来」这件事。
而「把自然语言精确写出来代码」这件事——大语言模型已经做得几乎不会出错。
整个过程画起来,是这样的:
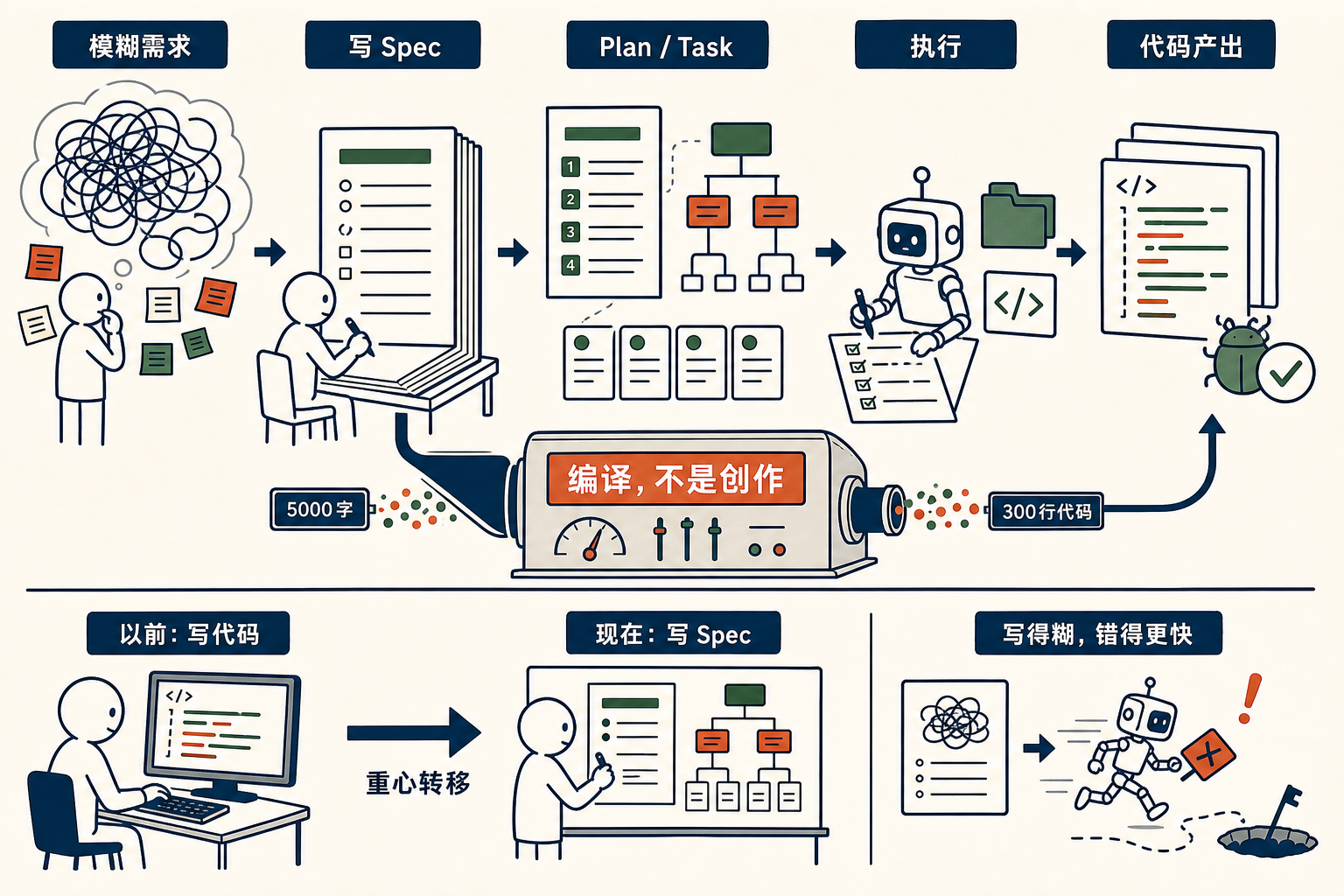
意识到这件事之后,我对工程师这个职业的看法整个变了。
以前我觉得,工程师 = 写代码的人。
现在我觉得,工程师 = 写 spec 的人。
代码这一层,正在被「编译」掉。它会一直存在,但不再是人的工作。就像 C 取代汇编之后,汇编没有消失,但绝大多数程序员不再写汇编了。
写代码的人会越来越少。 写 spec 的人会越来越多。
而且写 spec 这件事,比写代码难得多。
写代码是把一个明确的需求翻译成机器语言。 写 spec 是把一个不明确的需求翻译成明确的需求。
后者一直是更难的那一半。只是以前我们没意识到,因为它没法被 100% 表达——表达出来也没用,反正最后还是工程师边写边判断。
现在不一样了。你写 spec,它真的就照着 spec 来。一个字都不会偏。
这意味着以前那些「不严谨的需求」「想到哪儿写到哪儿的产品文档」「明知道有坑但反正工程师会处理」的工作方式——全都失效了。
不是被 AI 取代,是被一种新的工作方式取代。
新的工作方式叫:像写程序一样写文档,像写编译器一样写规范。
你以前写文档,是写给同事看。同事看不懂会问你。 你现在写文档,是写给一个不会问你、只会照做的极其聪明的执行者看。
写得清楚,它做得清楚。 写得糊涂,它做得糊涂。
但不管糊涂还是清楚——速度都比以前快 100 倍。
所以糊涂的代价,比以前大 100 倍。