题图:香港的蜗居
绘于:2020年3月
上一篇:卷积网络 CNN 学习笔记之一:我们是怎么认识0的
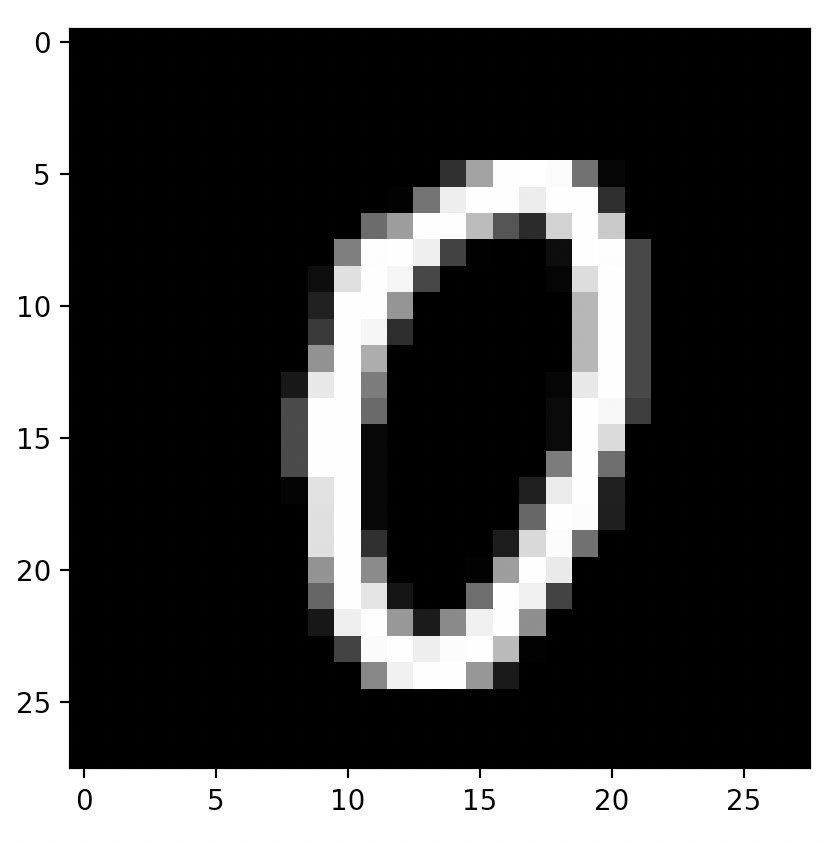
昨天留了个思考题,你的大脑是如何认识那个一圈的?
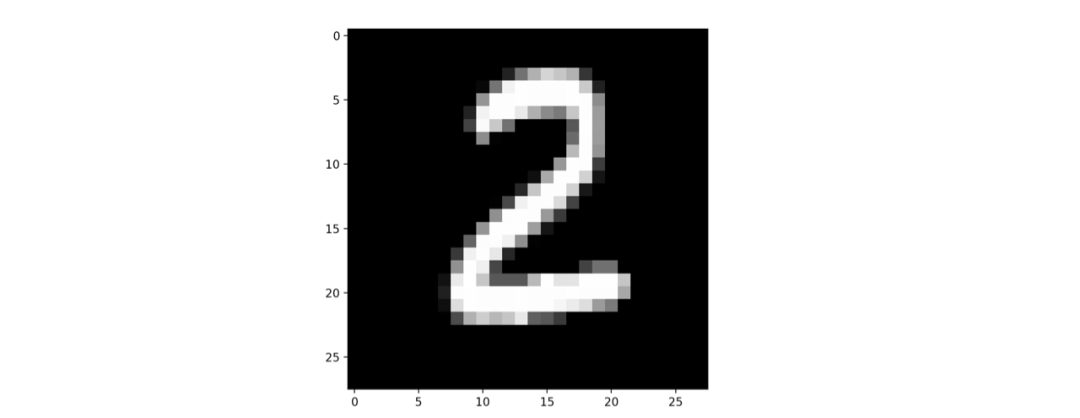
在你翻看 前一篇文章 以前,我再问你一个问题,你还记得上一次我们见到的 MNIST 数据集里面的那个 0 是如下哪一副吗?或者降低点难度,和如下哪一个 0 更接近呢?

训练集里的各种 0 (生成这个图的代码见 代码一)
或许你和我一样,记不太清了。没关系,这正是我要讲的,就是神经网络在处理信息的时候,当得到高一层的信息的时候就会忽略底层的信息,故意的遗忘。然后基于这一层的信息再往上推导一层更高层次的信息,再把下面的信息遗忘。如此很多层,直到得到最终的结论。这是一个不断丢失信息,形成一个新的信息的过程。
以上面的图像为例,原始的信息量其实非常大,那是一个 28 x 28 x 256 (也就是 28行,28列,每个点有256种可能性的图)的数据,也就是20万种可能性。而经过我们的人肉神经网络处理以后形成了 0 – 9 这10个数字中间的一个数字( 0 ),从 20 万种可能性到 10 种可能性这个过程就是神经网络的功劳。否则,人眼睛有六百万以上个视锥,眼睛看到的还是连续的视频的信息,要是我们的底层神经元不忽略掉这些信息而直接都传导到上一层神经元的话,我们脑子里面就会堆满了所有的细节,就无法思考更抽象的东西了。
小量维度的大量信息 –> 大量维度的小量信息
虽然图像的细节丢失了,但更高一层的认知在大脑里面诞生了。比如看了这个图像,我问你这几个问题:
这是一个黑白图像吗?【是】图像里面有一个圈吗?【是】图像里面线条连续吗?【是】这是个正方形图片吗?【是】
这样的问题我可以问几十个,对于这些问题我们的神经网络都可以回答,但这些问题的答案都没有直接写在原始的 28 x 28 的数据里面的,而是我们通过底层的信息,一层一层的抽象出来的。
请注意,你有没有发现最早的数据是在一个维度(黑或白的程度)上的大量数据,一步步的变成在多个维度的少量数据。“这是黑白图像吗”就是一个维度,这个维度的数据只有 一比特(是/不是);图像里面有一个圈吗?是另外一个维度,这样的维度很多很多。
人工智能就是从灰度或者彩色的图像里面,先认识边界,然后认识线,然后认识形状,然后再在这些圆和方的组合再认识人脸,然后再认识人,然后再从人认识场景等等。这样一层层的学习的。因为学些的层次很多,很深,我们常把这种模型叫做深度学习 – 深度就是很多层的意思。
人脑是怎么认识 0 的?
现在我们准备来解决这个问题。直接从原始的数据中看出来最终的数字不容易,但如果计算机把原始数据简化成如下这16个问题的答案,你是不是觉得容易一些?为了简化我用 0.0 代表没有,1.0 代表有。(实际情况可能不像 0 和 1 这么绝对,而是它们之间的一个数字)
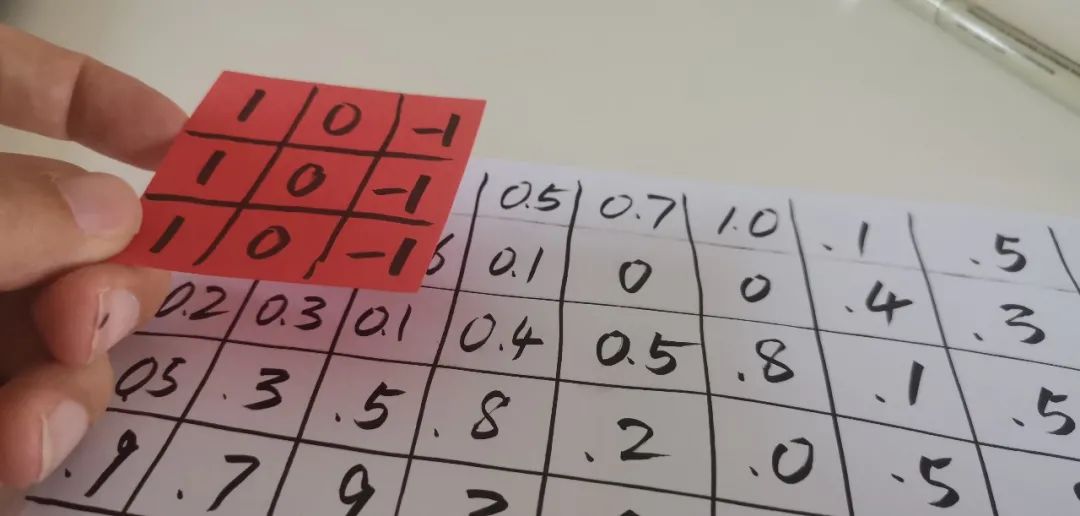
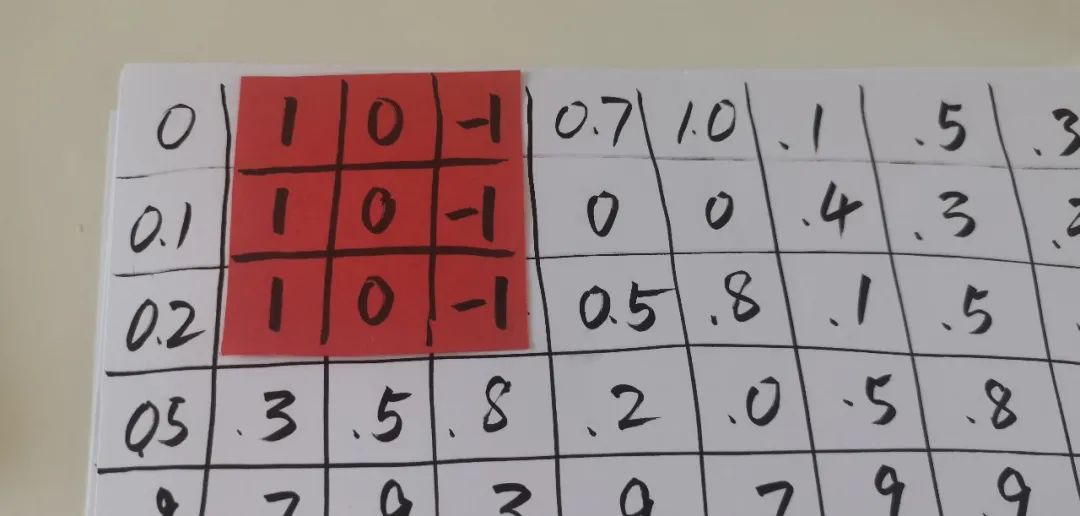
这个图片的左上角区域: 有 \ 反斜线吗? 【0.0】 有 | 垂直的线条吗? 【1.0】 有 / 正斜线吗? 【1.0】 有 – 横线吗? 【1.0】这个图片的右上角区域: 有 \ 反斜线吗? 【1.0】 有 | 垂直的线条吗? 【1.0】 有 / 正斜线吗? 【0.0】 有 – 横线吗? 【1.0】这个图片的左下角区域: 有 \ 反斜线吗? 【1.0】 有 | 垂直的线条吗? 【1.0】 有 / 正斜线吗? 【0.0】 有 – 横线吗? 【1.0】这个图片的右下角区域: 有 \ 反斜线吗? 【0.0】 有 | 垂直的线条吗? 【1.0】 有 / 正斜线吗? 【1.0】 有 – 横线吗? 【1.0】
如果你知道如上 16 个问题的答案,即使不看到原始的数据,也能脑补出来一个 0 的样子 (就是左上角有横线,然后转到右上到左下的斜线,然后是竖线,然后接左下角的四种线段)。
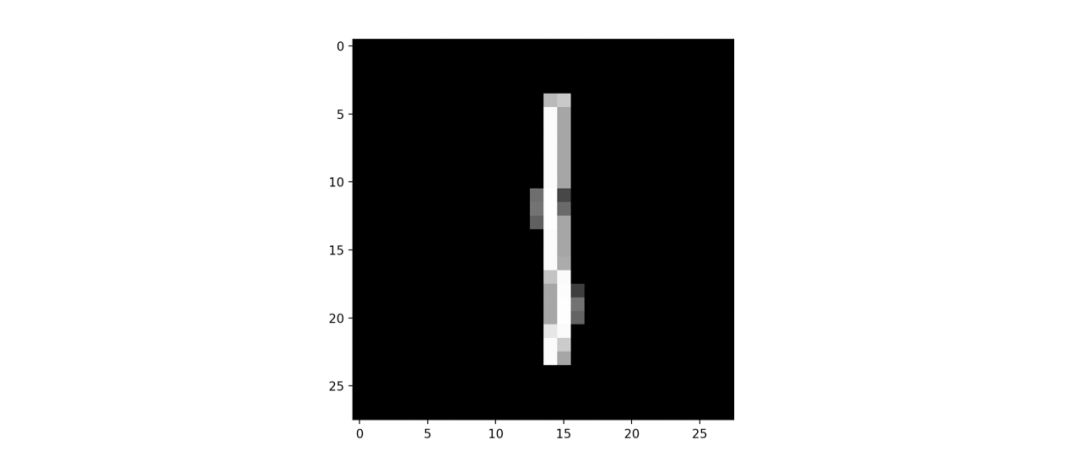
再看这张图呢?
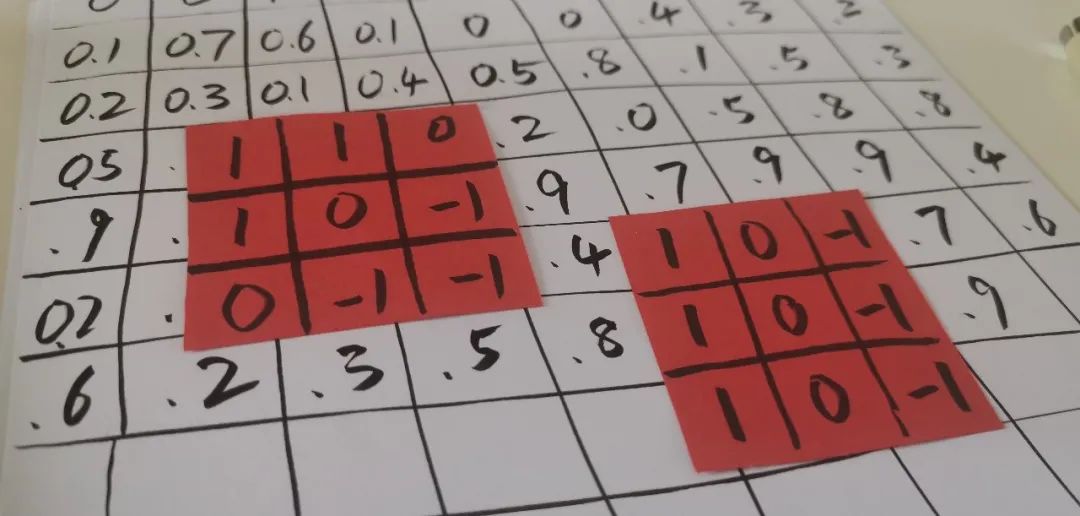
这个图片的左上角区域: 1 有 \ 反斜线吗? 【0.0】 2 有 | 垂直的线条吗?【1.0】 3 有 / 正斜线吗? 【0.0】 4 有 – 横线吗? 【0.0】这个图片的右上角区域: 5 有 \ 反斜线吗? 【0.0】 6 有 | 垂直的线条吗?【1.0】 7 有 / 正斜线吗? 【0.0】 8 有 – 横线吗? 【0.0】这个图片的左下角区域: 9 有 \ 反斜线吗? 【0.0】10 有 | 垂直的线条吗?【1.0】 11 有 / 正斜线吗? 【0.0】12 有 – 横线吗? 【0.0】这个图片的右下角区域:13 有 \ 反斜线吗? 【0.0】14 有 | 垂直的线条吗?【1.0】 15 有 / 正斜线吗? 【0.0】16 有 – 横线吗? 【0.0】
我猜这个数是 1 ,和你猜的一样吗?因为从数据上看,只有竖线,没有斜线和横线。。。。
到了这一步当然怎么做都行,最土的也是最不可扩展的,就是硬写程序:
如果 1,9,14,17 这四个问题的答案是 0 其他问题答案都是 1 的话,结果是 0如果所有的竖线的问题都是 1, 但是其他的问题答案都是 0 的话, 结果是 1
而实际上,大家还是用数学上面的线性回归来解决这样的问题。我们假设所有的问题都是 Y = a * X + b 这样的结构,只要有足够的(X,Y)数据可以让我们训练,找到 a 和 b 这两个参数就可以。也就是说,输入是 16 个数字 (x1, x2, x3, x4, x5, …, x16),分别代表对于如上 1 到 16 号问题的答案。输出是 10 个数字 (y1, y2, y3, …., y10) 分别代表这个数字是 0 – 9 的可能性。当我们有了60000多组这样的对应以后,就可以找到规律,再给我一组 x,我就可以输出一组 y 。这部分是最基础的线性代数,用 Excel 就可以轻松搞定的,还没有涉及最近出现的人工智能或者卷积神经网络。而接下来有趣的部分,就是如果从图像信息转换到这样的 16 个问题答案。这是后面的文章需要解决的问题。
多层的神经网络
当然到这里我们还远远没有回答 我们是怎么认识0的 。上面的部分其实希望在我全部讲完了以后再回过头来看才有可能看懂。
但我们先打住,看一段代码,然后用后面的几次文章通过从代码的角度,来细致的把刚才两段说的每一个细节了解清楚。
# 导入著名的 tensorflow。在命令行下用 pip3 install tensorflow 安装import tensorflow as tfimport numpy as npfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Conv2D, Flatten, MaxPooling2D, Dense, BatchNormalization# 从互联网上下载 mnist 数据集到本地 ~/.keras/datasets/mnist.npz# x_train, y_train 分别是是60000个训练图像和答案# x_test, y_test 分别是10000个测试图像和答案# 训练的算是日常习题,测试的才是高考题。为了计算机防止作弊,计算机读书的时候是不能看到高考试卷的(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()# 下面两句做一个非常简单的预处理,就是先把 60000 x 28 x 28 的三维数据扩展成 60000 x 28 x 28 x 1的四维数据# 这个对于数据没有任何变化,只是和Tensorflow要求的输入保持一致而已# 然后再都除以 255,使得数据都落在0-1之间,仅仅提高些计算效率,不怎么影响结果的x_train = x_train.astype(np.float32).reshape(*x_train.shape, 1)x_train /= 255# 翠花,上模型!如下就是传说中的卷积神经网络model = Sequential()model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Flatten())model.add(Dense(10, activation='softmax'))model.compile(optimizer='adam', metrics=['accuracy'], loss='sparse_categorical_crossentropy')model.fit(x_train, y_train, epochs=10)
大家可以先看看这个 Python 代码。这是一个很简单的训练卷积网络模型的代码,19行以前的都还是一些预处理的代码,真正有用的就只有19到25行这7行代码。而这个代码就是构建了一个仅仅四层的神经网络,分别是
-
第一层:卷积层 Conv2D
-
第二层:池化层 MaxPooling
-
第三层:压平层 Flatten
-
第四层:全连接层 Dense
也不要被这些名字吓倒。每一层,即便是不用任何类,仅仅是用原生的Python代码,也都是几行搞定的简单的运算。所以人工智能的代码是如此之简洁优美,却达到了以前复杂的系统几十年没有达到的高度。
如上代码执行一遍,一两分钟以后,就会得到一个训练好的模型,按照输出我们看到,它的识别准确率高达 99.73%
Epoch 10/101875/1875 [ - 10s 5ms/step - loss: 0.0083 - accuracy: 0.9973
我不得不承认,这个识别率已经远高于我这个人肉神经网络了,毕竟很多的数字我看半天也拿不准是多少。 😀
下一篇就要开始正儿八经的解释,人工智能网络的工作细节了。后台回复 “ AI ” 可以获得全系列文章和代码
后注:代码一:画出包括第 1001 个图像的 64 各种 0 的代码
import tensorflow as tfimport matplotlib.pyplot as plt(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()c = 0for index in range(850, 2000): if y_train[index] != 0: continue c += 1 if c > 64: continue ax = plt.subplot(8, 8, c) ax.set_xticks([]) ax.set_yticks([]) plt.imshow(x_train[index], cmap="gray")plt.show()